Mô hình, kiến trúc, công thức và mọi thứ đã tạo nên DeepSeek R1
Đi sâu nhưng đơn giản hóa mọi thứ để bạn có thể tạo nên một bản DeepSeek cho riêng mình ... why not ?

Nếu một ngày bạn nhận nhiệm vụ của công ty để tạo ra một mô hình tương tự DeepSeek thì đây là điểm bắt đầu hoàn hảo của bạn
DeepSeek R1 và Quy Trình Training từ Đầu
Mô hình, kiến trúc, công thức và mọi thứ đã tạo nên DeepSeek R1
Nếu bạn quan tâm đến AI, chắc hẳn bạn đã nghe nói về DeepSeek R1. Hiện tại, nó đang là xu hướng trong không gian LLM và vượt trội hơn cả các model mã nguồn mở và đóng.
Để mọi thứ trở nên dễ dàng, chúng ta sẽ sử dụng các flowchart vẽ tay và các phép tính đơn giản để làm rõ các khái niệm từ cơ bản.
Thực tế, chúng ta sẽ sử dụng chuỗi 2 + 3 * 4 = bao nhiêu? xuyên suốt bài blog này như một ví dụ để hướng dẫn bạn qua từng thành phần của DeepSeek tech report.
Siêu tóm tắt
Vậy, trước khi đi vào chi tiết kỹ thuật, một cái nhìn tổng quan nhanh là DeepSeek-R1 không được train từ đầu. Thay vào đó, họ bắt đầu với một LLM khá thông minh mà họ đã có DeepSeek-V3 nhưng họ nâng cấp và cho nó khả năng lập luận, một ... siêu động cơ lập luận.

Để làm được điều đó, họ đã sử dụng Reinforcement Learning, hay gọi tắt là RL, trong đó bạn thưởng cho LLM khi nó làm tốt việc lập luận và phạt nó khi ngược lại.

*AI model trả lời sai
Nhưng không chỉ là một phiên training đơn giản. Nó giống như một chuỗi các bước, một pipeline như họ gọi. Đầu tiên họ thử chỉ dùng RL thuần túy để xem liệu khả năng lập luận có tự xuất hiện hay không, đó là DeepSeek-R1-Zero, một thử nghiệm.
Đáng kinh ngạc là kết quả thử nghiệm này vượt xa kỳ vọng ban đầu. Dù chỉ là phiên bản sơ khai, DeepSeek-R1-Zero đã thể hiện khả năng lập luận ấn tượng, đạt điểm tương đương với các mô hình tiên tiến hơn như OpenAI-o1-0912 trong nhiều bài kiểm tra lập luận phức tạp. Đặc biệt, trong cuộc thi toán học danh giá AIME 2024 (American Invitational Mathematics Examination), DeepSeek-R1-Zero chứng minh khả năng giải quyết các bài toán khó với hiệu suất ngang ngửa các mô hình được phát triển công phu hơn. Đây là minh chứng rõ ràng cho thấy việc sử dụng Reinforcement Learning là một con đường hứa hẹn để nâng cao khả năng lập luận trong các mô hình ngôn ngữ lớn.
Sau đó với DeepSeek-R1 thực sự, họ tổ chức nó có hệ thống hơn với các giai đoạn khác nhau. Họ cung cấp một số dữ liệu ban đầu để bắt đầu, sau đó là RL, rồi thêm dữ liệu, rồi lại RL... giống như việc lên cấp từng bước một!
Mục đích chính là làm cho các model ngôn ngữ này giỏi hơn nhiều trong việc suy nghĩ qua các vấn đề và đưa ra câu trả lời thông minh, không chỉ đơn thuần là nhả ra các từ ngữ nghe có vẻ hợp lý.
Vậy đó, đó là phiên bản tóm tắt ngắn gọn trước khi chúng ta đi vào chi tiết phức tạp của từng bước.
DeepSeek V3 (MOE) Suy Nghĩ Như Thế Nào?
Như tôi đã nói trước đó, việc training DeepSeek R1 không được xây dựng từ đầu mà họ sử dụng DeepSeek V3 như một base model. Vì vậy chúng ta cần hiểu V3 hoạt động như thế nào và tại sao nó được gọi là MOE?

DeepSeek V3 hoạt động với hai đường dẫn chính. Khi bạn nhập một câu hỏi, nó đầu tiên đi qua hệ thống bộ nhớ để nhanh chóng xây dựng ngữ cảnh bằng cách tìm thông tin liên quan. Hãy nghĩ về nó như việc nhanh chóng nhớ lại những tình huống tương tự mà bạn đã gặp trước đây.
Điểm mạnh chính của DeepSeek V3 chính là hệ thống ra quyết định thông minh. Sau khi phân tích và hiểu đầu vào của người dùng, mô hình sử dụng một router tinh vi để đánh giá tác vụ và phân luồng xử lý theo hai hướng khác nhau:
- Đường dẫn xử lý nhanh: Dành cho các tác vụ đơn giản như trả lời câu hỏi thông thường hoặc yêu cầu cơ bản, giúp tiết kiệm tài nguyên và đáp ứng nhanh chóng
- Hệ thống chuyên gia: Được kích hoạt khi gặp các vấn đề phức tạp đòi hỏi phân tích sâu, suy luận logic hoặc kiến thức chuyên môn cao cấp
Router này chính là yếu tố then chốt biến DeepSeek V3 thành một mô hình kết hợp chuyên gia (Mixture of Experts - MOE)
Cơ chế router thông minh này hoạt động như một bộ phân luồng, tự động phân tích và điều hướng mỗi yêu cầu đến đúng thành phần chuyên gia phù hợp nhất, giúp tối ưu hóa hiệu suất xử lý và chất lượng câu trả lời.

"Hệ thống 1 hoạt động tự động và nhanh chóng, với ít hoặc không có nỗ lực và không có cảm giác kiểm soát có ý thức. Hệ thống 2 phân bổ sự chú ý cho các hoạt động tinh thần đòi hỏi nỗ lực, bao gồm các tính toán phức tạp. Hoạt động của Hệ thống 2 thường gắn liền với trải nghiệm chủ quan về tác nhân, lựa chọn và tập trung." - Daniel Kahneman, Think Fast and Slow
Cấu trúc hai hệ thống này phản ánh hoàn hảo cách thức hoạt động của DeepSeek V3. Đường dẫn xử lý nhanh giống như Hệ thống 1 của bộ não con người - tự động, tiết kiệm năng lượng và hiệu quả cho những tác vụ đơn giản. Trong khi đó, hệ thống chuyên gia phức tạp hoạt động tương tự Hệ thống 2 - có chủ đích, sâu sắc và được thiết kế đặc biệt cho những vấn đề đòi hỏi suy luận phức tạp.
Các câu hỏi đơn giản nhận được câu trả lời trực tiếp nhanh chóng thông qua đường dẫn nhanh, trong khi các truy vấn phức tạp nhận được sự chú ý chi tiết thông qua hệ thống chuyên gia. Cuối cùng, những phản hồi này được kết hợp thành các đầu ra rõ ràng, chính xác.
DeepSeek V3 như là Policy Model (Actor) Trong Thiết Lập RL
Bây giờ chúng ta đã có cái nhìn tổng quan về cách DeepSeek V3 suy nghĩ, và nó là điểm khởi đầu cho việc triển khai DeepSeek R1, khi nói điểm khởi đầu tôi muốn nói rằng nó đã tạo ra phiên bản DeepSeek R1 zero, một phiên bản ban đầu có một số lỗi trong đó trước khi phiên bản cuối cùng được tạo ra.
Phiên bản ban đầu (R1 Zero) được tạo ra bằng cách sử dụng Reinforcement Learning trong đó DeepSeek V3 đóng vai trò như một RL agent (actor thực hiện hành động). Hãy cùng trực quan hóa cách nó hoạt động.
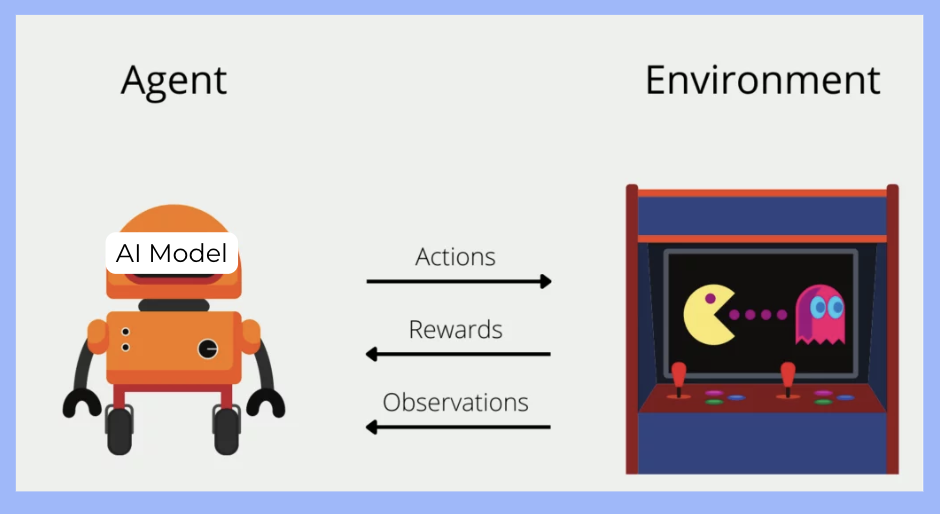
Ôn lại cơ chế hoạt động của RL:
- Actions: Tác động vào môi trường
- Rewards: Phản hồi chất lượng hành động
- Observations: Thu thập trạng thái môi trường
Hiểu đơn giản: AI Agent quan sát → suy luận bằng ML Model → hành động → đạt mục tiêu.

RL agent (DeepSeek V3) bắt đầu bằng việc thực hiện một Action, nghĩa là nó tạo ra một câu trả lời và một số lập luận cho một vấn đề được quan sát bởi Observations. Mục tiêu của nó là đưa ra một lập luận đạt được một Reward tốt nhất có thể.
Ví dụ:
-
Observations: Câu hỏi
2 + 3 * 4 = bao nhiêu? -
Action: Câu trả lời và lập luận:
<think>Okay, so I need to figure out what 2 plus 3 times 4 is. Hmm, let me think ... </think> <answer> The expression (2 + 3 \times 4) follows the order of operations (PEMDAS/BODMAS), where multiplication is performed before addition. Multiply first: (3 \times 4 = 12). Then add: (2 + 12 = 14). Answer: (\boxed{14}) </answer> -
Reward: Điểm số được tính toán từ câu trả lời và lập luận
Sau khi thực hiện một hành động, Nó sẽ nhận được một Reward. Reward này giống như phản hồi, nó cho DeepSeek V3 base model biết hành động của nó tốt như thế nào. Một Reward tích cực có nghĩa là nó đã làm đúng điều gì đó, có thể là đưa ra câu trả lời chính xác hoặc lập luận tốt. Tín hiệu phản hồi này sau đó quay trở lại DeepSeek-V3-Base, giúp nó học và điều chỉnh cách thực hiện hành động trong tương lai để nhận được Rewards tốt hơn.
Trong các phần tiếp theo, chúng ta sẽ thảo luận về thiết lập RL này với reward model và thuật toán RL mà họ đã sử dụng và thử giải quyết nó bằng text input của chúng ta.
Thuật toán GRPO
GRPO là gì ?
GRPO (Group Reinforcement Policy Optimization) là thuật toán RL được phát triển đặc biệt cho việc huấn luyện các mô hình ngôn ngữ lớn (LLMs). Thuật toán này được phát triển dựa trên nền tảng của PPO (Proximal Policy Optimization), nhưng có một điểm khác biệt quan trọng. Trong khi PPO yêu cầu một mô hình critic riêng biệt để đánh giá hành động, GRPO sử dụng cơ chế nhóm (group) để ước tính giá trị advantage mà không cần đến mô hình phụ. Điều này giúp GRPO giải quyết hiệu quả những thách thức chính khi áp dụng RL vào quá trình huấn luyện các mô hình ngôn ngữ lớn.
Thuật Toán GRPO Hoạt Động Như Thế Nào?
Việc training các LLM cực kỳ tốn kém về mặt tính toán và RL còn làm tăng thêm độ phức tạp.
Vì vậy, có nhiều thuật toán RL có sẵn, nhưng RL truyền thống sử dụng thứ gọi là "critic" để giúp phần ra quyết định chính ("actor" tức là DeepSeek V3) như bạn đã biết. Critic này thường có kích thước và độ phức tạp tương đương với actor, điều này về cơ bản làm tăng gấp đôi chi phí tính toán.
Tuy nhiên, GRPO làm khác biệt vì nó tìm ra một baseline, một loại điểm tham chiếu cho các hành động tốt trực tiếp từ kết quả nó nhận được từ một nhóm các hành động. Vì điều này, GRPO không cần một model critic riêng biệt. Điều này tiết kiệm nhiều tính toán và làm cho mọi thứ hiệu quả hơn.

Nó bắt đầu với một câu hỏi hoặc prompt được đưa vào model, gọi là "Old Policy". Thay vì chỉ nhận một câu trả lời, GRPO hướng dẫn Old Policy tạo ra một nhóm các câu trả lời khác nhau cho cùng một câu hỏi. Mỗi câu trả lời này sau đó được đánh giá và được cho một điểm thưởng, phản ánh mức độ tốt hoặc mong muốn của nó.
GRPO tính toán "Advantage" cho mỗi câu trả lời bằng cách so sánh nó với chất lượng trung bình của các câu trả lời khác trong nhóm của nó. Các câu trả lời tốt hơn trung bình nhận được advantage dương, và những câu trả lời kém hơn nhận được advantage âm. Quan trọng là điều này được thực hiện mà không cần một model critic riêng biệt.
Các điểm advantage này sau đó được sử dụng để cập nhật Old Policy, làm cho nó có khả năng tạo ra các câu trả lời tốt hơn trung bình trong tương lai. Model được cập nhật này trở thành "Old Policy" mới và quá trình lặp lại, cải thiện model một cách lặp đi lặp lại.
Hàm Mục Tiêu của GRPO
Siêu tóm tắt:
Hàm mục tiêu của GRPO có hai mục tiêu, một là đưa ra đầu ra tốt (rewards cao) trong khi cũng đảm bảo quá trình training ổn định và không vượt quá tầm kiểm soát. Hàm gốc khá đáng sợ nhưng chúng ta sẽ viết lại nó thành dạng đơn giản hơn mà không làm mất đi ý nghĩa thực sự của nó.
Với mỗi câu hỏi 𝑞, GRPO lấy mẫu một nhóm các đầu ra {o1, o2, · · · , oG} từ old policy (DeepSeek V3-Base) πθold và sau đó tối ưu hóa mô hình πθ bằng cách tối đa hóa mục tiêu sau:
\[ \jmath_{GRPO}(\theta)=\mathbb{E}[{q \sim P(Q), {o_i}{i=1}^G \sim \pi{\theta_{old}}(O|q)}] \ \frac{1}{G} \sum_{i=1}^G (min(\frac{\pi_{\theta_{old}}(o_i|q)}{\pi_{\theta}(o_i|q)}A_i, clip(\frac{\pi_{\theta_{old}}(o_i|q)}{\pi_{\theta}(o_i|q)}, 1-\epsilon, 1+\epsilon)A_i) - \beta \mathbb{D}{KL}(\pi{\theta}||\pi_{ref})) \tag{1} \]
- Kỳ vọng (Expectation): \( \mathbb{E}[{q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)}] \)- Đây là giá trị trung bình khi chúng ta lấy mẫu nhiều câu hỏi q từ phân phối P(Q) và với mỗi câu hỏi, lấy mẫu một nhóm G câu trả lời từ policy cũ \( \pi_{\theta_{old}} \)
- Trung bình nhóm: \( \frac{1}{G} \sum_{i=1}^G (...) \) - Tính trung bình các giá trị trong nhóm G câu trả lời.
- Tỷ lệ xác suất (Probability Ratio): \( \frac{\pi_{\theta_{old}}(o_i|q)}{\pi_{\theta}(o_i|q)} \) - So sánh xác suất của câu trả lời oi giữa policy cũ và policy mới. Probability Ratio cho chúng ta biết liệu khả năng đưa ra câu trả lời này tăng hay giảm với model mới. Cụ thể, nó xem xét:
- Khả năng trả lời với Model Mới: Model mới có khả năng đưa ra một câu trả lời cụ thể như thế nào.
- Khả năng trả lời với Model Cũ: Model cũ có khả năng đưa ra cùng một câu trả lời như thế nào.
- Advantage \( A_i \) - Đánh giá câu trả lời oi tốt hơn hay kém hơn so với trung bình nhóm.
\[ A_i = \frac{ri−mean({r_1,r_2,…,r_G})}{std({r_1,r_2,…,r_G})} \]
Dễ hiểu thì: \[ A_i = \frac{\text{Điểm của câu trả lời i} - \text{Điểm trung bình của nhóm}}{\text{Độ lệch chuẩn của nhóm}} \]
- Điểm của câu trả lời: Phần thưởng được trao cho câu trả lời cụ thể.
- Điểm trung bình của Nhóm: Điểm thưởng trung bình của tất cả các câu trả lời trong nhóm.
- Độ lệch chuẩn (phân tán) của Điểm trong Nhóm: Mức độ biến thiên trong điểm số của các câu trả lời trong nhóm.
- Hàm clip: \( clip(\frac{\pi_{\theta_{old}}(o_i|q)}{\pi_{\theta}(o_i|q)}, 1-\epsilon, 1+\epsilon) \) - Giới hạn tỷ lệ xác suất trong khoảng \( [1-\epsilon, 1+\epsilon] \) để tránh thay đổi quá lớn.
- KL-divergence: \( \beta \mathbb{D}_{KL}(\pi_{\theta}||\pi_{ref}) \) - Đo lường sự khác biệt giữa policy hiện tại và policy tham chiếu, với \( \beta \) là hệ số điều chỉnh.
Công thức KL-divergence (Kullback-Leibler divergence) này đo lường sự khác biệt giữa hai phân phối xác suất: phân phối của policy hiện tại \( \pi_{\theta} \) và phân phối tham chiếu πref. Trong ngữ cảnh của GRPO, đây là một thành phần quan trọng giúp kiểm soát quá trình học.
\[ \mathbb{D}_{KL}(\pi_{\theta}||\pi_{ref})= \frac{\pi_{ref}(o_i|q)}{\pi_{\theta}(o_i|q)} -\log \frac{\pi_{ref}(o_i|q)}{\pi_{\theta}(o_i|q)} \tag{2} \]
Công thức này có hai phần chính:
- Tỷ lệ giữa hai phân phối: \( \frac{\pi_{ref}(o_i|q)}{\pi_{\theta}(o_i|q)} \) - Đây là tỷ lệ giữa xác suất mà policy tham chiếu và policy hiện tại tạo ra đầu ra oi cho câu hỏi q.
- Logarit của tỷ lệ đó: \( \log \frac{\pi_{ref}(o_i|q)}{\pi_{\theta}(o_i|q)} \) - Logarit của tỷ lệ này.
KL-divergence đóng vai trò như một "hàm phạt" trong hàm mục tiêu của GRPO. Nó ngăn không cho policy mới \( \pi_{\theta} \) đi quá xa so với policy tham chiếu \( \pi_{ref} \), giúp đảm bảo quá trình học ổn định. Khi hai phân phối càng giống nhau, giá trị KL-divergence càng nhỏ.
Hệ số \( \beta \) trước KL-divergence trong hàm mục tiêu GRPO điều chỉnh mức độ ảnh hưởng của hàm phạt này. Giá trị β lớn hơn sẽ khiến model ít thay đổi hơn so với policy tham chiếu, trong khi giá trị nhỏ hơn cho phép model thay đổi nhiều hơn để tối ưu hóa phần thưởng.
Đây là cách DeepSeek đảm bảo rằng quá trình học không chỉ tập trung vào việc tối đa hóa phần thưởng mà còn duy trì sự ổn định trong quá trình huấn luyện, tránh những thay đổi đột ngột có thể dẫn đến sự sụp đổ của hiệu suất model.
Ý nghĩa thực tế
Công thức này thực hiện hai nhiệm vụ quan trọng:
- Tối ưu hóa phần thưởng: Phần đầu tiên min(πθold(oi|q)πθ(oi|q)Ai,clip(...)) khuyến khích model tăng xác suất cho các câu trả lời có advantage dương (tốt hơn trung bình) và giảm xác suất cho các câu trả lời có advantage âm (kém hơn trung bình).
- Đảm bảo ổn định: Hàm clip và thành phần KL-divergence giúp kiểm soát mức độ thay đổi của policy, tránh những thay đổi đột ngột có thể làm hỏng quá trình học.
Đơn giản thì nó như thế này:
\[ \text{Mục tiêu} = \frac{1}{n} \sum_{q=1}^n{(\text{Reward câu trả lời}_q - \text{Độ khác biệt so với model cũ}_q)} \]
Phát biểu: GRPO tối đa hóa hàm mục tiêu với giá trị của từng câu hỏi nhưng sẽ giảm đi nếu nó quá khác biệt so với kết quả hiện tại. giúp quá trình học ổn định hơn và tránh được hiện tượng "policy collapse" khi model thay đổi quá nhanh.
💀💀💀 Đến đây là quá đủ toán cho ngày hôm nay rồi.
Nhìn dưới dạng đối tượng thì sao ?

Đây là mô tả dễ tưởng tượng của quá trình training DeepSeek R1 với GRPO.
Reward Modeling cho DeepSeek R1 Zero
Bây giờ chúng ta đã hiểu các khái niệm lý thuyết chính, hãy sử dụng text input của chúng ta để tìm hiểu cách reward modeling này hoạt động để tạo ra R1 Zero.
Hãy nhớ rằng, đối với R1 Zero, họ giữ mọi thứ đơn giản và trực tiếp. Thay vì sử dụng một neural network phức tạp để đánh giá các câu trả lời (như họ có thể làm trong các giai đoạn sau), họ đã sử dụng một hệ thống reward dựa trên quy tắc.
Đối với bài toán toán học của chúng ta: "2 + 3 * 4 = bao nhiêu?"

Kiểm Tra Dựa Trên Quy Tắc
Hệ thống biết câu trả lời đúng là 14. Nó sẽ xem xét output được tạo ra bởi DeepSeek V3 (RL agent của chúng ta) và cụ thể là kiểm tra bên trong các thẻ
Nếu tag <answer> chứa "14" (hoặc một cái gì đó tương đương về mặt số học), nó nhận được reward dương, giả sử là +1. Nếu sai, nó nhận được reward 0, hoặc có thể là reward âm (mặc dù bài báo tập trung vào 0 để đơn giản hóa ở giai đoạn này).
Reward về Độ Chính Xác
Mô hình reward về độ chính xác đánh giá liệu câu trả lời có đúng hay không. Đây là một phần quan trọng trong quá trình huấn luyện DeepSeek R1 Zero.
Đối với các bài toán toán học có kết quả xác định, mô hình được yêu cầu cung cấp câu trả lời cuối cùng trong một định dạng cụ thể (ví dụ: trong thẻ <answer>). Điều này cho phép việc kiểm tra tính đúng đắn dựa trên quy tắc một cách đáng tin cậy.
Tương tự, đối với các bài toán lập trình như LeetCode, một trình biên dịch có thể được sử dụng để tạo ra phản hồi dựa trên các test case đã được định nghĩa trước. Ví dụ:
-
Đối với bài toán toán học: Nếu câu trả lời trong thẻ
<answer>chứa giá trị đúng (như "14" trong ví dụ của chúng ta), model nhận được reward dương. -
Đối với bài toán lập trình: Code được trích xuất từ câu trả lời sẽ được chạy qua một bộ test case. Nếu tất cả test case đều pass, model nhận được reward dương.
-
Đối với câu hỏi đa lựa chọn: Nếu lựa chọn trong thẻ
<answer>khớp với đáp án đúng, model nhận được reward dương.
Cách tiếp cận dựa trên quy tắc này đặc biệt hiệu quả trong giai đoạn đầu của quá trình huấn luyện vì nó rõ ràng, minh bạch và ít có khả năng bị "reward hacking" - hiện tượng model tìm ra cách để tối đa hóa reward mà không thực sự cải thiện hiệu suất thực tế.
Format Rewards
Nhưng DeepSeek R1 Zero cũng cần học cách cấu trúc lập luận của nó một cách phù hợp và để làm điều đó, các thẻ
Kiểm tra xem output của model có đúng cách đóng gói quá trình lập luận trong
Bài báo DeepSeek R1 đề cập rõ ràng việc tránh các neural reward model cho DeepSeek-R1-Zero để ngăn chặn reward hacking và giảm độ phức tạp trong giai đoạn thăm dò ban đầu này
Training Template cho Reward
Để reward model hiệu quả, các nhà nghiên cứu đã thiết kế một template training cụ thể. Template này hoạt động như một bản thiết kế, hướng dẫn DeepSeek-V3-Base về cách cấu trúc các phản hồi của nó trong quá trình Reinforcement Learning.
Hãy xem template gốc và phân tích từng phần:
Một cuộc hội thoại giữa Người dùng và Trợ lý. Người dùng đặt câu hỏi, và
Trợ lý giải quyết nó. Trợ lý trước tiên suy nghĩ về quá trình lập luận
trong tâm trí và sau đó cung cấp câu trả lời cho người dùng. Quá trình
lập luận và câu trả lời được đóng gói lần lượt trong các thẻ <think> </think>
và <answer> </answer>, ví dụ: <think> quá trình lập luận ở đây </think>
<answer> câu trả lời ở đây </answer>. User: {prompt}. Assistant:
{prompt} là nơi chúng ta đặt bài toán toán học của mình, như 2 + 3 * 4 = bao nhiêu?. Phần quan trọng là những thẻ
Khi chúng ta train DeepSeek-R1-Zero, chúng ta cung cấp các prompt sử dụng template này. Đối với ví dụ của chúng ta, input sẽ trông như thế này:
Một cuộc hội thoại giữa User và Assistant. User đặt một câu hỏi, và
Assistant giải quyết nó. Assistant trước tiên suy nghĩ về quá trình lập luận
trong tâm trí và sau đó cung cấp câu trả lời cho user. Quá trình
lập luận và câu trả lời được đóng gói lần lượt trong các thẻ <think> </think>
và <answer> </answer>, ví dụ: <think> quá trình lập luận ở đây </think>
<answer> câu trả lời ở đây </answer>. User: 2 + 3 * 4 = bao nhiêu?. Assistant:
Và chúng ta mong đợi model tạo ra một output tuân theo template, như:
<think>
Thứ tự các phép tính:
nhân trước cộng sau. 3 * 4 = 12. 2 + 12 = 14
</think>
<answer>
14
</answer>
Thú vị là, đội ngũ DeepSeek cố tình giữ template này đơn giản và tập trung vào cấu trúc. Nó tránh áp đặt bất kỳ ràng buộc cụ thể về nội dung nào lên chính quá trình lập luận.
Quy Trình Training RL cho DeepSeek R1 Zero
Mặc dù bài báo không chỉ rõ chính xác dataset ban đầu cho việc RL pre-training, chúng ta giả định rằng nó nên tập trung vào lập luận.
Bước đầu tiên họ thực hiện là tạo ra nhiều output có thể bằng cách sử dụng old policy là model DeepSeek-V3-Base trước khi cập nhật reinforcement learning. Trong một lần training, chúng ta giả định GRPO lấy mẫu một nhóm G = 4 output.
Ví dụ, model tạo ra bốn output sau cho text input của chúng ta 2 + 3 * 4 = bao nhiêu?
Giả sử ta có 4 reward với kết quả như sau: 0.1 + 1.1 + 1 +0.1
- o1:
<think> 2 + 3 = 5, 5 * 4 = 20 </think> <answer> 20 </answer>(Thứ tự phép tính sai) = 0.1 điểm - o2:
<think> 3 * 4 = 12, 2 + 12 = 14 </think> <answer> 14 </answer>(Đúng) = 1.1 điểm - o3:
<answer> 14 </answer>(Đúng, nhưng thiếu thẻ<think>) = 1.0 điểm - o4:
<think> ...một số lập luận vô nghĩa... </think> <answer> 7 </answer>(Sai và lập luận kém) = 0.1 điểm
o ở đây là viết tắt của output. o1 = output 1, không phải chatgpt o1
Mỗi output sẽ được đánh giá và được gán một reward dựa trên độ chính xác và chất lượng lập luận.
Để hướng dẫn model hướng tới lập luận tốt hơn, hệ thống reward dựa trên quy tắc được áp dụng. Mỗi output được gán một reward dựa trên:
- Accuracy Reward: Liệu câu trả lời có đúng không.
- Format Reward: Liệu các bước lập luận có được định dạng đúng với thẻ
<think>hay không.

Ý tưởng là Model nên học cách ưu tiên các output có rewards cao hơn trong khi giảm việc tạo ra các output không chính xác hoặc không đầy đủ.

Để đánh giá mức độ đóng góp của mỗi output vào hiệu suất tổng thể của model, chúng ta tính toán giá trị advantage dựa trên các reward. Advantage là thước đo quan trọng giúp tối ưu hóa policy bằng cách củng cố những output chất lượng cao và hạn chế những output kém hiệu quả.
Để làm điều đó, hãy tính toán reward trung bình trước.
\[ \text{Reward trung bình} = \frac{0.1 + 1.1 + 1 +0.1}{4} = 0.575 \]
\[ \text{Độ lệch chuẩn reward} = \sqrt{\frac{(0.1-0.575)^2 + (1.1-0.575)^2 + (1-0.575)^2 + (0.1-0.575)^2}{4}} \approx 0.5 \]
Bây giờ để tính advantage của mỗi output.
\[ A_i = \frac{r_i - \text{Reward trung bình}}{\text{Độ lệch chuẩn reward}} \]
Tại đây, \( r_i \) là reward của output thứ \( i \), áp dụng lần lượt với list output: [0.1 + 1.1 + 1 + 0.1]
\[ A_1 = \frac{0.1-0.575}{0.5} \sim -0.95 \\ A_2 = \frac{1.1-0.575}{0.5} \sim 1.05 \\ A_3 = \frac{1-0.575}{0.5} \sim 0.85 \\ A_4 = \frac{0.1-0.575}{0.5} \sim -0.95 \]

Kết quả phân tích advantage cho thấy hai nhóm output rõ rệt: o2 và o3 có advantage dương (1.05 và 0.85), đây là những output chất lượng cao cần được khuyến khích trong quá trình huấn luyện. Ngược lại, o1 và o4 có advantage âm (-0.95 cho cả hai), cho thấy đây là những output kém chất lượng mà model nên học cách tránh tạo ra trong tương lai.
GRPO sau đó sử dụng các advantage đã tính toán để cập nhật policy model (DeepSeek-V3-Base) để tăng xác suất tạo ra các output có advantage cao (như o2 và o3) và giảm xác suất của các output có advantage thấp hoặc âm (như o1 và o4).
Update điều chỉnh trọng số của model dựa trên:
- Policy Ratios: Xác suất tạo ra một output dưới policy mới so với policy cũ.
- Cơ chế Clipping: Ngăn chặn các cập nhật quá lớn có thể làm mất ổn định training.
- KL-Divergence Penalty: Đảm bảo rằng các cập nhật không đi quá xa so với model gốc.

Điều này đảm bảo rằng trong lần lặp tiếp theo, model sẽ có khả năng cao hơn để tạo ra các bước lập luận đúng trong khi giảm các phản hồi không chính xác hoặc không đầy đủ.
Vì vậy RL là một quá trình lặp đi lặp lại. Các bước trên được lặp lại hàng nghìn lần sử dụng các bài toán lập luận khác nhau. Mỗi lần lặp dần dần cải thiện khả năng của model để:
- Thực hiện thứ tự phép tính đúng
- Cung cấp các bước lập luận logic
- Sử dụng định dạng phù hợp một cách nhất quán
Vòng lặp training tổng thể trông như thế này:

Theo thời gian, model học từ những sai lầm của nó, trở nên chính xác và hiệu quả hơn trong việc giải quyết các bài toán lập luận. 🚀🧠.
Tới đây là bạn đã hiểu về cách Deep Seek R1 Zero được tạo ra.
Hành trình tiếp tục, hai vấn đề chính với R1 Zero

Sau khi DeepSeek-R1 Zero được tạo ra bằng quy trình training RL trên model V3, các nhà nghiên cứu thấy model đã được train hoạt động rất tốt trong các bài kiểm tra lập luận, thậm chí đạt điểm tương tự như các model tiên tiến hơn như OpenAI-01–0912 trong các nhiệm vụ như AIME 2024. Điều này cho thấy việc sử dụng reinforcement learning (RL) để khuyến khích lập luận trong các model ngôn ngữ lớn là một hướng tiếp cận đầy hứa hẹn.
Nhưng họ cũng nhận thấy DeepSeek-R1-Zero có một số vấn đề chính cần khắc phục để sử dụng trong thực tế và nghiên cứu rộng rãi hơn.
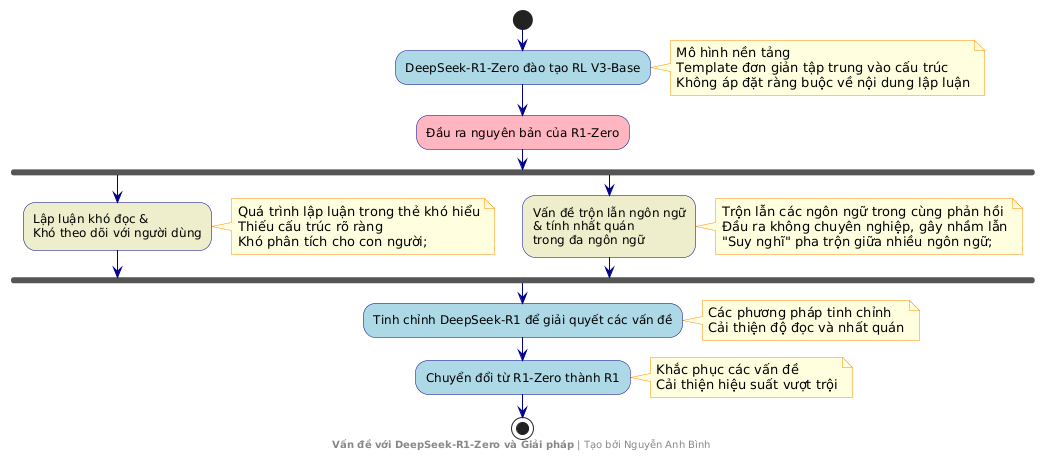
Theo các nhà nghiên cứu của DeepSeek, template được thiết kế có chủ đích đơn giản và tập trung vào cấu trúc. Template này tránh áp đặt bất kỳ ràng buộc cụ thể nào về nội dung lên quá trình lập luận. Ví dụ, template không yêu cầu:
- "Bạn phải sử dụng lập luận từng bước" (Nó chỉ đề cập đến "quá trình lập luận", để model tự xác định ý nghĩa của điều này)
- "Bạn phải sử dụng lập luận phản chiếu"
- "Bạn phải áp dụng một chiến lược giải quyết vấn đề cụ thể"
Tuy nhiên, vấn đề chính phát sinh là các quá trình lập luận bên trong thẻ
Một vấn đề khác là việc trộn lẫn ngôn ngữ, khi được hỏi các câu hỏi đa ngôn ngữ, model đôi khi trộn lẫn các ngôn ngữ trong cùng một phản hồi, dẫn đến các output không nhất quán và gây nhầm lẫn. Nếu bạn hỏi nó các câu hỏi bằng, ví dụ, tiếng Tây Ban Nha. Đột nhiên, "suy nghĩ" của nó sẽ là một sự pha trộn lộn xộn giữa tiếng Anh và tiếng Tây Ban Nha, không hề chuyên nghiệp! Những vấn đề này, lập luận lộn xộn và nhầm lẫn ngôn ngữ, là những rào cản rõ ràng.
Đây là hai lý do chính họ chuyển đổi model R1 Zero ban đầu của họ thành R1
- Lập luận khó đọc và khó theo dõi: Quá trình lập luận trong thẻ
thường khó hiểu, thiếu cấu trúc rõ ràng và gây khó khăn cho con người trong việc phân tích. - Vấn đề trộn lẫn ngôn ngữ và tính nhất quán trong đa ngôn ngữ: Model thường trộn lẫn các ngôn ngữ trong cùng một phản hồi, tạo ra đầu ra không chuyên nghiệp và gây nhầm lẫn khi xử lý các câu hỏi đa ngôn ngữ.
Trong phần tiếp theo, chúng ta sẽ xem xét cách họ cải thiện model R1 zero của họ thành model R1, điều này đã thúc đẩy hiệu suất của nó và giúp nó vượt trội hơn tất cả các model khác, cả mã nguồn mở và đóng.
Cold Start Data
Vì vậy để khắc phục các vấn đề của R1 Zero và thực sự giúp DeepSeek lập luận đúng đắn, các nhà nghiên cứu đã thực hiện Thu thập Cold Start Data và bao gồm Supervised Fine Tuning.
Bạn có thể nghĩ về nó như việc cung cấp cho model một nền tảng tốt về lập luận trước khi training RL thực sự mạnh mẽ. Về cơ bản, họ muốn dạy DeepSeek-V3 Base cách lập luận tốt trông như thế nào và cách trình bày nó rõ ràng.
Hai Phương Pháp Tạo Chuỗi Suy Luận (Chain-of-Thought)
Để cải thiện khả năng lập luận của DeepSeek, các nhà nghiên cứu đã triển khai hai phương pháp chính:

-
Direct Prompting: Trong phương pháp này, model được hướng dẫn trực tiếp để hiển thị quá trình lập luận của mình. Không cần cung cấp ví dụ, chỉ đơn giản yêu cầu model "Giải bài toán này, hiển thị lập luận theo từng bước và kiểm tra lại". Model phải tự học cách tạo ra chuỗi suy luận có cấu trúc.
-
Learning from Examples: Phương pháp thứ hai dựa trên việc cung cấp cho model các ví dụ few-shot với chuỗi suy luận chi tiết. Model học cách bắt chước kiểu lập luận này, áp dụng cấu trúc tương tự cho các vấn đề mới.
Mặc dù hai phương pháp có cách tiếp cận khác nhau, cả hai đều hướng tới mục tiêu tạo ra đầu ra có cấu trúc tương tự với chuỗi suy luận rõ ràng, giúp model phát triển khả năng lập luận mạnh mẽ hơn.
Phương pháp 1: Few shot Prompting với Long CoT
Họ đã cung cấp cho DeepSeek-V3 Base một vài ví dụ về câu hỏi cùng với các giải pháp thực sự chi tiết, từng bước một, gọi là Chain-of-Thought (CoT). Ý tưởng là để model học bằng ví dụ và bắt đầu bắt chước phong cách lập luận từng bước này.
Đối với bài toán ví dụ của chúng ta 2 + 3 * 4 = bao nhiêu?, họ có thể hiển thị các prompt như thế này:
Ví dụ Bài toán với Lời giải:
Bài toán: Căn bậc hai của 9 cộng với 5 là bao nhiêu?
Lời giải:
<special_token>
Đầu tiên, tìm căn bậc hai của 9, đó là 3.
Sau đó, cộng 5 vào 3. 3 + 5 bằng 8.
</special_token>
Tóm tắt: Đáp án là 8.
Bài toán: Tàu hỏa di chuyển với tốc độ 60 dặm/giờ trong 2 giờ, quãng đường đi được là bao nhiêu?
Lời giải:
<special_token>
Sử dụng công thức: Quãng đường = Tốc độ nhân Thời gian.
Tốc độ là 60 dặm/giờ, Thời gian là 2 giờ. Quãng đường = 60 * 2 = 120 dặm.
</special_token>
Tóm tắt: Tàu hỏa đi được 120 dặm.
Bài toán: 2 + 3 * 4 = bao nhiêu?
Lời giải:
Những <special_token> đó chỉ là các dấu hiệu để tách biệt các bước lập luận khỏi phần tóm tắt, làm cho nó rõ ràng để model học cấu trúc.
Sau khi thấy những ví dụ này, model nên học cách đưa ra câu trả lời theo định dạng tương tự, như thế này cho 2 + 3 * 4 = bao nhiêu?
<special_token>
Theo thứ tự thực hiện phép tính (PEMDAS/BODMAS),
thực hiện phép nhân trước phép cộng. Vậy, đầu tiên tính 3 * 4 = 12.
Sau đó, cộng 2 vào 12. 2 + 12 = 14.
</special_token>
Tóm tắt: Đáp án là 14.
*PEMDAS/BODMAS: Thứ tự thực hiện phép tính: Dấu ngoặc đơn, Số mũ, Nhân/Chia, Cộng/Trừ
Phương pháp 2: Prompt trực tiếp (Direct Prompting)
Một cách khác họ thu thập dữ liệu là bằng cách trực tiếp yêu cầu model không chỉ giải quyết vấn đề mà còn phải hiển thị rõ ràng lập luận của nó từng bước một và sau đó kiểm tra lại câu trả lời của nó.
Điều này nhằm thúc đẩy việc giải quyết vấn đề cẩn thận và suy nghĩ kỹ lưỡng hơn.
Đối với 2 + 3 * 4 = bao nhiêu? prompt có thể là:
Bài toán: Giải bài này, hiển thị lập luận từng bước và kiểm tra lại cách giảigiải:
2 + 3 * 4 = bao nhiêu?
Và họ mong đợi một output bao gồm cả các bước lập luận và phần xác minh:
<special_token>
To solve 2 + 3 * 4, I need to use order of
operations. Multiplication comes before addition.
Step 1: Calculate 3 * 4 = 12.
Step 2: Add 2 to the result from step 1: 2 + 12 = 14.
Verification: Checking order of operations again, yes, multiplication
is before addition. Calculation looks right.
</special_token>
Summary: The answer is 14.
Post Processing Refinement
Một phương pháp khác mà nhóm nghiên cứu đã áp dụng là tận dụng các kết quả từ model R1 Zero. Mặc dù R1 Zero còn nhiều hạn chế, nó vẫn có khả năng lập luận cơ bản. Nhóm nghiên cứu đã thu thập các đầu ra từ R1 Zero, sau đó thuê người gắn nhãnnhãn chuyên nghiệp cải thiện chất lượng, cấu trúc và sửa lỗi trong các câu trả lời.
Ví dụ minh họa quá trình cải thiện:
<think> ừm... nhân 3 với 4... được 12... sau đó cộng thêm 2...</think>
<answer> 14 </answer>
Đầu ra ban đầu từ R1 Zero (chưa cấu trúc, thiếu chuyên nghiệp):
<special_token>
Lập luận: Để giải bài toán này, chúng ta sử dụng thứ tự thực hiện phép tính,
thực hiện phép nhân trước phép cộng.
Bước 1: Nhân 3 với 4, được 12.
Bước 2: Cộng 2 vào kết quả: 2 + 12 = 14.
</special_token>
Tóm tắt: Đáp án là 14.
Trực quan hóa quy trình tinh chỉnh hoạt động như thế này:

Giá Trị của Cold Start Data
Dữ liệu khởi đầu (Cold Start Data) mà nhóm nghiên cứu thu thập được đặc biệt có giá trị vì ba yếu tố chính:
-
Chất Lượng Lập Luận Vượt Trội: Mỗi mẫu dữ liệu đều trình bày quá trình lập luận chi tiết, rõ ràng theo từng bước, giúp mô hình học cách giải quyết vấn đề một cách có hệ thống.
-
Cấu Trúc Thống Nhất: Việc sử dụng định dạng
<special_token>tạo ra sự nhất quán trong toàn bộ tập dữ liệu, giúp mô hình dễ dàng nhận diện và xử lý thông tin. -
Độ Tin Cậy Cao: Toàn bộ dữ liệu đều được con người kiểm tra và lọc bỏ các ví dụ kém chất lượng, đảm bảo mô hình chỉ học từ những mẫu đáng tin cậy.
Với bộ Cold Start Data chất lượng cao này, nhóm nghiên cứu đã tiến hành bước tiếp theo: Huấn luyện có giám sát (Supervised Fine-Tuning - SFT) để dạy mô hình DeepSeek-V3 cách tạo ra các chuỗi lập luận có cấu trúc tốt.
Supervised Fine-Tuning
Supervised Fine-Tuning (SFT) là một trong những khái niệm cơ bản nhất trong Machine Learning, đặc biệt là khi so sánh với phương pháp Reinforcement Learning phức tạp đã đề cập ở trên. Về bản chất, SFT hoạt động theo một nguyên tắc đơn giản: chúng ta cung cấp cho mô hình các cặp "input-output mong muốn" và dạy nó cách tạo ra output chính xác từ input.
Quy trình này có thể được tóm tắt qua các bước sau:
-
Thu thập dữ liệu huấn luyện: Tạo hàng nghìn hoặc hàng vạn cặp input-output mẫu, trong đó output là câu trả lời lý tưởng mà chúng ta muốn mô hình học cách tạo ra.
-
Đưa input vào mô hình: Mô hình nhận input và tạo ra một output dự đoán.
-
Tính toán sai số (loss): So sánh output dự đoán với output mong muốn để xác định mức độ sai lệch.
-
Tối ưu hóa: Sử dụng các thuật toán tối ưu hóa (như gradient descent) để điều chỉnh các tham số của mô hình, giúp giảm thiểu sai số trong các lần dự đoán tiếp theo.
-
Lặp lại quá trình: Quá trình này được lặp lại hàng nghìn lần với các cặp dữ liệu khác nhau, giúp mô hình dần dần học cách tạo ra output chính xác hơn.
Điểm mạnh của SFT nằm ở tính đơn giản và hiệu quả của nó. Thay vì phải thiết kế các hệ thống phức tạp để đánh giá và khen thưởng hành vi như trong RL, SFT chỉ đơn giản là "học theo ví dụ" - một phương pháp trực quan và dễ hiểu hơn nhiều.
Với DeepSeek R1, Ý tưởng cốt lõi của SFT Stage 1 là sử dụng supervised learning để dạy DeepSeek-V3-Base cách tạo ra các output lập luận có chất lượng cao, có cấu trúc.
Về cơ bản, chúng ta đang cho model xem nhiều ví dụ về lập luận tốt và yêu cầu nó học cách bắt chước phong cách đó.
Đối với SFT, chúng ta cần định dạng Cold Start Data của mình thành các cặp input-target. Đối với mỗi bài toán lập luận trong dataset của chúng ta, chúng ta tạo một cặp như thế này:
Input = Prompt hoặc mô tả vấn đề
User: 2 + 3 * 4 = bao nhiêu? Assistant:
Đây là những gì chúng ta đưa vào model và target của chúng ta là lập luận và câu trả lời được cấu trúc tốt tương ứng
<special_token> Theo thứ tự thực hiện phép tính (PEMDAS/BODMAS) ... </special_token>
Tóm tắt: Đáp án là 14.
Đây là output lý tưởng mà chúng ta muốn model học để tạo ra.
Chúng ta đang nói với model:
Khi bạn thấy input này (câu hỏi), chúng tôi muốn bạn tạo ra output target này (lập luận tốt và câu trả lời)
Thay vì giải thích nó bằng văn bản chi tiết và làm cho bạn khó hiểu, hãy trực quan hóa nó trước để có một lời giải thích SFT dễ dàng hơn

Quá trình fine-tuning được thực hiện theo các bước sau:
-
Chuẩn bị dữ liệu: Chúng ta cung cấp cho model các cặp dữ liệu gồm câu hỏi (prompt) và lập luận mẫu có cấu trúc tốt (target reasoning).
-
Dự đoán token tiếp theo: Model DeepSeek-V3-Base nhận input và cố gắng dự đoán từng token tiếp theo trong chuỗi lập luận.
-
Tính toán độ lệch (loss): Hệ thống so sánh token mà model dự đoán với token thực tế trong target. Khoảng cách giữa dự đoán và thực tế càng lớn thì loss càng cao.
-
Cập nhật tham số model: Sử dụng kỹ thuật backpropagation và các thuật toán tối ưu hóa, hệ thống điều chỉnh các trọng số của model để giảm thiểu loss.
-
Lặp lại quá trình: Các bước trên được lặp lại nhiều lần với hàng nghìn cặp dữ liệu khác nhau. Qua mỗi vòng lặp, model dần dần cải thiện khả năng tạo ra lập luận có cấu trúc tốt, gần với mẫu target hơn.
Quá trình này giúp model học cách tạo ra các lập luận có cấu trúc rõ ràng, dễ hiểu và theo đúng format mong muốn.
Học Tập Định Hướng Lập Luận (Reasoning Oriented Learning) - Nâng Cấp Khả Năng Tư Duy Cho DeepSeek-V3
Sau khi xây dựng nền tảng lập luận cho DeepSeek-V3 qua quá trình Fine-tuning có giám sát (SFT), nhóm nghiên cứu tiếp tục áp dụng Reinforcement Learning để mài giũa khả năng này. Phương pháp mới, gọi là Reasoning Oriented Learning, tập trung tối ưu hóa quá trình lập luận của mô hình thông qua hệ thống phần thưởng thông minh.
Đột Phá Từ Hệ Thống Phần Thưởng
Dù vẫn sử dụng thuật toán GRPO, điểm nổi bật trong giai đoạn này là việc bổ sung Phần Thưởng Nhất Quán Ngôn Ngữ (Language Consistency Reward). Điều này giải quyết vấn đề từ phiên bản trước (R1 Zero) - hiện tượng mô hình trộn lẫn ngôn ngữ khi trả lời. Cụ thể:
- Nếu câu hỏi bằng tiếng Anh, toàn bộ lập luận và đáp án phải giữ nguyên ngôn ngữ này.
- Phần thưởng mới khuyến khích mô hình duy trì tính nhất quán, đồng thời kết hợp với phần thưởng cho độ chính xác.
Công Thức Tính Phần Thưởng Tổng Hợp
Tổng phần thưởng được tính bằng:
Tổng Reward = (Trọng số Độ Chính Xác × Reward Chính Xác) + (Trọng số Ngôn Ngữ × Reward Nhất Quán)
Với trọng số mặc định: 1 cho độ chính xác và 0.2 cho nhất quán ngôn ngữ.
Ví Dụ Minh Họa
-
Output o1 (Sai Toán, Đúng Ngôn Ngữ):
- Lập luận:
<think> 2 + 3 = 5, 5 * 4 = 20 </think> <answer> 20 </answer>(tiếng Anh). - Reward Chính Xác: 0 (đáp án sai).
- Reward Ngôn Ngữ: 1 (100% tiếng Anh).
- Tổng Reward:
(1×0) + (0.2×1) = 0.2.
- Lập luận:
-
Output o2 (Đúng Toán, Đúng Ngôn Ngữ):
- Lập luận:
<think> 3 * 4 = 12, 2 + 12 = 14 </think> <answer> 14 </answer>(tiếng Anh). - Reward Chính Xác: 1 (đáp án đúng).
- Reward Ngôn Ngữ: 1.
- Tổng Reward:
(1×1) + (0.2×1) = 1.2.
- Lập luận:
Kết quả cho thấy: Ngay cả khi trả lời sai, mô hình vẫn nhận được phần thưởng nhỏ nếu giữ nguyên ngôn ngữ. Điều này cân bằng giữa việc khuyến khích tư duy đúng và hình thức trình bày phù hợp.

Quy Trình Huấn Luyện RL
- Tạo nhiều output cho cùng một câu hỏi.
- Tính reward tổng hợp, bao gồm cả nhất quán ngôn ngữ.
- Ước lượng lợi thế (advantage) của từng output bằng GRPO.
- Huấn luyện mô hình ưu tiên các output có lợi thế cao.
- Lặp lại để tối ưu hóa liên tục.
Nhờ cơ chế này, DeepSeek-V3 không chỉ cải thiện độ chính xác mà còn nâng cao khả năng trình bày lập luận một cách mạch lạc và chuyên nghiệp.
(Due to technical issues, the search service is temporarily unavailable.)
Rejection Sampling: Bí Quyết Lọc Dữ Liệu "Vàng" Cho AI Lập Luận
Khi đào tạo AI giải quyết bài toán phức tạp, chất lượng dữ liệu quan trọng hơn số lượng. Hiểu điều này, DeepSeek đã áp dụng Rejection Sampling - kỹ thuật "đãi cát tìm vàng" để chọn lọc những ví dụ training hoàn hảo nhất.
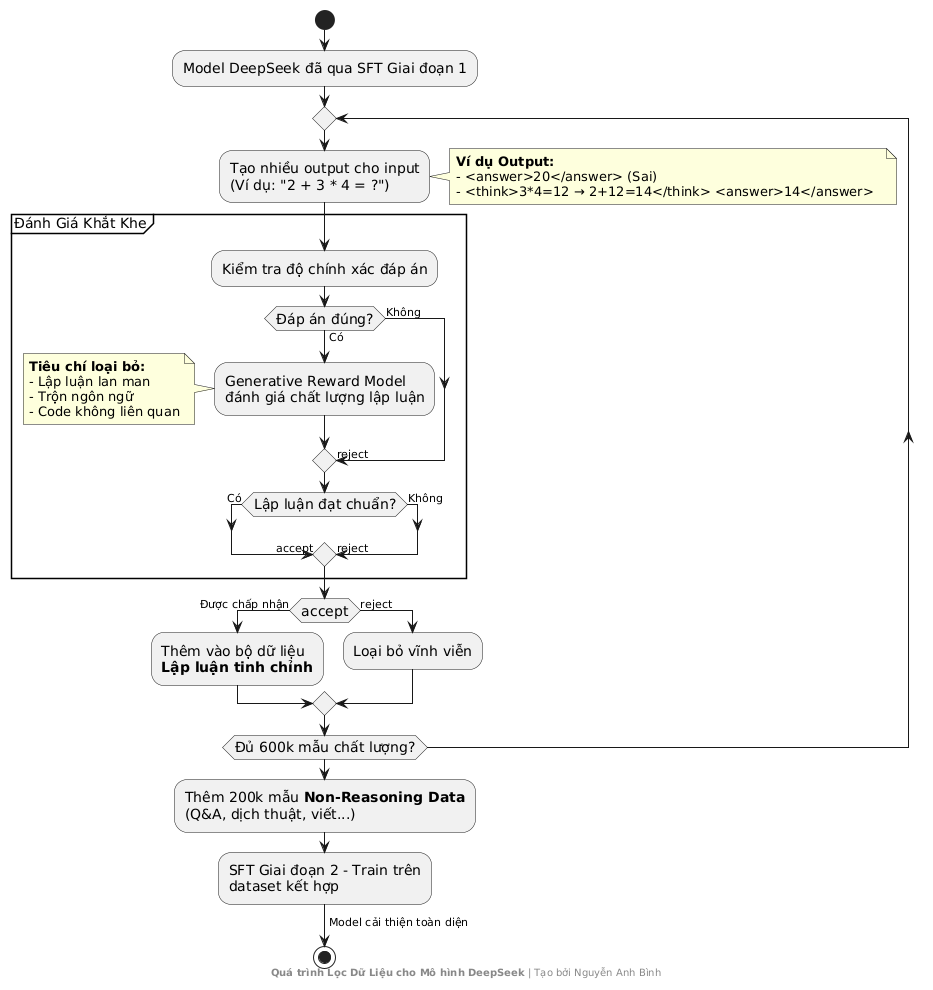
Cách Thức Hoạt Động
-
Tạo Nhiều Phiên Bản Trả Lời
- Ví dụ với câu hỏi "2 + 3 * 4 = bao nhiêu?", model tạo ra hàng loạt đáp án:
- ❌
<answer>20</answer>(Sai: Tính từ trái sang phải) - ✅
<think>3*4=12 → 2+12=14</think> <answer>14</answer>(Đúng kèm lập luận)
- ❌
- Ví dụ với câu hỏi "2 + 3 * 4 = bao nhiêu?", model tạo ra hàng loạt đáp án:
-
Đánh Giá Khắt Khe
- Độ chính xác: Kiểm tra đáp án cuối cùng (ví dụ: "14" mới đúng).
- Chất lượng lập luận: Sử dụng Generative Reward Model (mô hình AI chuyên chấm điểm lập luận) để phân tích:
- 🚫 Loại bỏ lập luận lan man, trộn ngôn ngữ, hoặc chèn code vô nghĩa.
- ✅ Chỉ giữ lại lập luận logic, dễ hiểu, và đúng trọng tâm.
-
Kết Quả: Thu về 600,000 mẫu lập luận chất lượng cao sau khi lọc.
Tại Sao Cần Thêm Dữ Liệu "Không Lập Luận"?
- Cân Bằng Kỹ Năng: Bổ sung 200,000 mẫu cho tác vụ thông thường (viết email, dịch thuật, Q&A...) để AI không thành "học sinh chuyên Toán" thiếu kỹ năng mềm.
- Linh Hoạt Hóa: Một số tác vụ phức tạp vẫn cần Chain-of-Thought (giải thích từng bước) để tăng độ tin cậy.
Giai Đoạn Cuối: Tinh Chỉnh Toàn Diện
DeepSeek tiếp tục huấn luyện SFT Giai đoạn 2 trên bộ dữ liệu kết hợp:
- Lập luận tinh chỉnh: Những "viên ngọc" từ Rejection Sampling.
- Dữ liệu đa nhiệm: Đảm bảo AI vừa giỏi tư duy, vừa linh hoạt trong giao tiếp.
Ví dụ hoàn hảo: Bài toán "2 + 3 * 4" với lập luận chặt chẽ đã trở thành mẫu training chuẩn mực, giúp AI hiểu sâu bản chất thay vì học vẹt.
Bài Học Từ Rejection Sampling
"Không phải cứ nhiều dữ liệu là tốt. 10 ví dụ xuất sắc mang lại giá trị hơn 1000 ví dụ tầm thường."
- Kỹ thuật này không chỉ nâng cao năng lực lập luận mà còn giúp AI tránh xa thói quen xấu như trả lời đại khái, lập luận thiếu căn cứ.
(Due to technical issues, the search service is temporarily unavailable.)
RL Stage 2: Định Hình AI An Toàn & Hữu Ích
Sau giai đoạn SFT Stage 2, DeepSeek V3 đã thành thạo lập luận toán học, giao tiếp mạch lạc và xử lý tác vụ đa dạng. Nhưng để trở thành trợ lý AI đáng tin cậy, nó cần học cách cân bằng giữa hiệu suất và giá trị con người. Đây chính là mục tiêu của Reinforcement Learning Giai đoạn 2 (RL Stage 2) – bước hoàn thiện cuối cùng biến DeepSeek-R1 thành phiên bản "chuẩn mực" nhất.

3 Trụ Cột Đánh Giá Mới
Với ví dụ kinh điển "2 + 3 * 4 = bao nhiêu?", hệ thống reward giờ đây không chỉ dừng ở độ chính xác mà còn xem xét:
-
Tính Hữu Ích
- Đánh giá khả năng cung cấp ngữ cảnh (ví dụ: giải thích quy tắc nhân chia trước cộng trừ).
- Ví dụ tốt: "Theo thứ tự phép tính, ta thực hiện 3×4=12 trước, sau đó 2+12=14".
-
Tính Vô Hại
- Quét toàn bộ output để phát hiện nội dung thiên vị, nhạy cảm, hoặc thông tin sai lệch.
- Ví dụ loại bỏ: "Kết quả là 14 – đây cũng là số may mắn của tôi!" (thêm thông tin cá nhân không cần thiết).
-
Độ Chính Xác
- Tiêu chuẩn cơ bản: Đáp án cuối cùng phải đúng (ví dụ: 14).
Công thức Reward tổng hợp:
Total Reward = (Độ Chính Xác × 1) + (Tính Hữu Ích × 0.5) + (Tính Vô Hại × 0.5)
Dữ Liệu Training Đa Nhiệm
Để model học cách cân bằng, dữ liệu được pha trộn đa dạng:
- Bài toán lập luận (Toán, logic, lập trình).
- Hỏi đáp thông thường (Kiến thức tổng hợp, dịch thuật).
- Tác vụ sáng tạo (Viết email, tóm tắt văn bản).
- Dữ liệu sở thích con người (So sánh cặp output để dạy AI phân biệt "tốt/xấu").
Quy Trình Huấn Luyện
- Lặp lại chu kỳ RL (sử dụng GRPO):
- Tạo output → Tính reward đa tiêu chí → Cập nhật model.
- Đánh giá định kỳ trên benchmark để đo lường tiến bộ.
- Dừng lại khi model đạt cân bằng tối ưu giữa:
- Khả năng giải quyết vấn đề.
- Tính an toàn & tự nhiên trong giao tiếp.
Kết Quả: DeepSeek-R1 Ra Đời
Sau hàng nghìn lần lặp, DeepSeek-R1 chính thức trở thành phiên bản:
- Chính xác: Giải toán phức tạp không lỗi.
- Hữu ích: Cung cấp giải thích rõ ràng, có ngữ cảnh.
- An toàn: Từ chối trả lời các câu hỏi nhạy cảm hoặc đưa thông tin gây hiểu lầm.
Ví dụ hoàn hảo: Khi hỏi "Cách tính GDP?", DeepSeek-R1 không chỉ đưa công thức mà còn giải thích ngắn gọn về ứng dụng thực tế và cảnh báo các hạn chế của chỉ số này – thể hiện sự thấu hiểu và trách nhiệm.
Bài học từ RL Stage 2: Một AI xuất sắc không chỉ cần thông minh, mà còn phải biết "nghĩ cho con người" – đó là chìa khóa để công nghệ trở nên đáng tin cậy và hữu ích toàn diện.
(Due to technical issues, the search service is temporarily unavailable.)
Distillation: "Thu Nhỏ" Trí Tuệ AI, Mở Rộng Tiềm Năng Ứng Dụng

Sau khi tạo ra DeepSeek-R1 - model AI "khổng lồ" về khả năng lập luận, đội ngũ DeepSeek tiếp tục thu nhỏ tri thức của nó vào các model nhẹ hơn, qua quy trình Distillation (chưng cất tri thức). Đây là cách họ biến AI "hạng nặng" thành phiên bản tiết kiệm tài nguyên mà vẫn mạnh mẽ!
5 Bước Distillation Đơn Giản
-
Chuẩn Bị Dữ Liệu Vàng
- Tuyển chọn 800,000 mẫu lập luận chất lượng cao từ DeepSeek-R1.
-
"Thầy Giáo" AI Truyền Đạt Tri Thức
- Teacher Model: DeepSeek-R1 đóng vai trò "giáo viên", tạo output mẫu cho từng câu hỏi.
- Ví dụ: Với bài toán "2 + 3 * 4", nó xuất ra "3×4=12 → 2+12=14" kèm giải thích chi tiết.
-
"Học Trò" Model Nhỏ Học Hỏi
- Student Model: Các model nhẹ như Qwen-1.5B, Llama-14B đóng vai "học sinh".
- Phương pháp: Fine-tuning có giám sát (SFT) để bắt chước cách trả lời của "thầy".
-
Tối Ưu Hóa Hiệu Suất
- Loại bỏ các layer thừa, tinh chỉnh tham số để model nhỏ chạy nhanh hơn 2-3 lần.
- Duy trì ~80% năng lực lập luận so với bản gốc.
-
Ra Mắt Phiên Bản "Mini"
- Kết quả: Các model như DeepSeek-R1-Mini ra đời, chỉ vài GB nhưng giải toán "ngang cơ" model trăm GB.
Tại Sao Cần Distillation?
- Triển Khai Dễ Dàng: Model nhẹ chạy tốt trên điện thoại, máy tính cá nhân.
- Tiết Kiệm Chi Phí: Giảm 90% chi phí điện toán so với model lớn.
- Bảo Mật: Không cần dùng model gốc - tránh rủi ro lộ dữ liệu nhạy cảm.
Ví dụ thực tế: DeepSeek-R1-Mini (7B parameters) có thể giải bài toán phức tạp trong 2 giây, trong khi bản gốc (100B+ parameters) cần 10 giây với phần cứng đắt tiền.
Ứng Dụng Distillation
- Giáo Dục: Tích hợp vào app học tập để giải toán, luyện viết.
- Customer Service: Chatbot xử lý 1000+ yêu cầu/giây với độ chính xác cao.
- Research: Dùng làm baseline cho các thử nghiệm AI chi phí thấp.
Trí tuệ không nằm ở kích thước - tinh chỉnh khéo léo giúp AI "nhỏ mà có võ", mở ra kỷ nguyên AI nhỏ nhe, không cần 100 GPU H100 để host Large Language Model. Và thực tế được chứng minhminh này đã kéo tụt 14% giá cổ phiếu của NVDIA
Tóm tắt hành trình xây dựng DeepSeek R1.
Long story short
-
Nền tảng từ DeepSeek-V3 (MOE):
Kế thừa kiến trúc "Hệ thống 1 & 2" giống não người, phân luồng tác vụ thông minh qua router. Xử lý nhanh cho vấn đề đơn giản, kích hoạt chuyên gia cho bài toán phức tạp. -
DeepSeek-R1-Zero (Thử nghiệm RL):
Dùng GRPO - thuật toán RL không cần critic model, tối ưu qua advantage nhóm. Reward đơn giản dựa trên độ chính xác và định dạng, cho kết quả bất ngờ: ngang OpenAI-o1 trong bài toán AIME 2024. -
Khắc phục hạn chế bằng Cold Start Data:
- Thu thập dữ liệu lập luận chất lượng qua Direct Prompting và Learning from Examples.
- Fine-tuning (SFT) để định hình cấu trúc lập luận rõ ràng:
<think>phân tích →<answer>kết luận.
-
RL Stage 1 (Reasoning Oriented Learning):
Bổ sung Language Consistency Reward (trọng số 0.2), giải quyết vấn đề trộn ngôn ngữ. Công thức reward tổng hợp:
Total Reward = Accuracy + 0.2*Language_Consistency -
Rejection Sampling & SFT Stage 2:
Lọc 600K mẫu "vàng" từ 2M output, kết hợp 200K tác vụ thường để cân bằng kỹ năng. Tạo bộ dữ liệu đa nhiệm hoàn chỉnh. -
RL Stage 2 (Đa tiêu chí):
Tích hợp 3 yếu tố:Accuracy(1.0)Helpfulness(0.5)Harmlessness(0.5)
→ Tối ưu model vừa thông minh, vừa an toàn.
-
Distillation tri thức:
"Chưng cất" DeepSeek-R1 thành phiên bản mini (7B params) qua 800K mẫu vàng, duy trì 80% năng lực với tốc độ x2-3 lần.
Kết quả: DeepSeek-R1 trở thành LLM đầu tiên kết hợp thành công tư duy hệ thống + RL đa tiêu chí + tối ưu hoá phân tán, mở đường cho thế hệ AI vừa mạnh mẽ vừa thực tế. Chi phí hosting và vận hành của model cũng được giảm rất nhiều tới mức bạn có thể self-host một mô hình Deepseek chỉ với 8GB GPU hoặc 2 con H100, tùy yêu cầu về độ thông minh mà bài toán của bạn cần.
tham khảo thêm tại: DeepSeek Local: Cách Tự Host DeepSeek -Bảo Mật và ổn định
Nếu bạn muốn bàn luận thêm thông tin chi tiết về training cũng như triển khai AI - AI Agent cho doanh nghiệp, đừng ngần ngại liên hệ với mình qua Contact nhé! 👍😃



![[Digital Signal Processing] Chẩn đoán nhịp tim bất thường](/content/images/size/w600/2025/03/Omelet.tech-4.png)