
malware-analysis
Một buổi sáng ... bị lừa đảo gọi
Phân tích tĩnh và động một APK Flutter đóng gói bằng packer thương mại, dùng NetEase NIM làm kênh truyền và một lớp AES tự viết để né kiểm duyệt.
security
Vụ HF bị đấm gần gây cũng là một sự vụ đáng chú ý. AI hay không AI đây nhỉ ?

postgresql
Mình đổi EvoBright LMS sang UUID vì lý do bảo mật. Rồi tự chạy benchmark 60 triệu dòng và đọc RFC. Cả hai đều nói mình sai ở chỗ mình không ngờ.
ai
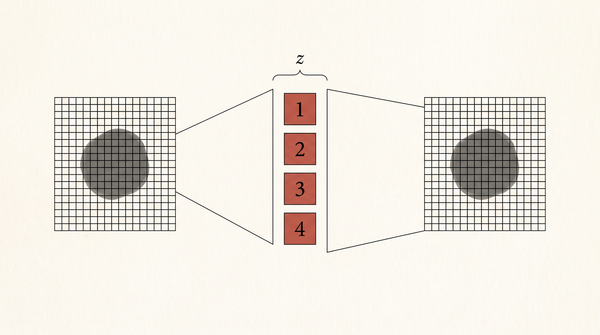
Latent space không giữ cái bạn cho là quan trọng. Nó giữ cái mà hàm mất mát bắt nó giữ. Một bài có công thức, có thí nghiệm chạy được, và vài con số 2026 khó chịu.

ARP spoofing, MAC flooding, VLAN hopping, STP takeover, rogue DHCP - tại sao tầng Data Link vẫn là chỗ dễ bị mò nhất trong enterprise LAN, kể từ một switch phòng lab tới một datacenter Fortune 500.

Các bài về DeepSeek v4 đang được spam ầm ầm trên các group. Các bài đó đúng 80% nhưng 20% còn lại là sai hoặc gây hiểu nhầm. Và tôi nghĩ nếu bạn thật sự muốn hiểu thì bạn nên đọc bài viết này và paper gốc.
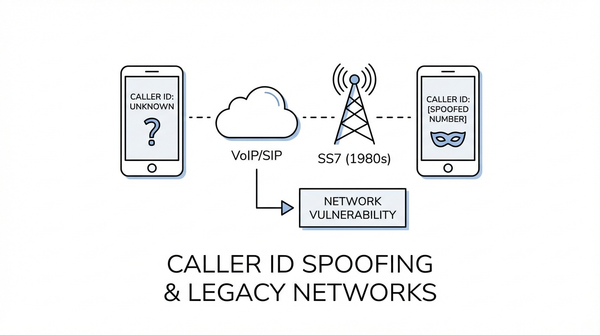
Caller ID spoofing hoạt động vì SS7 thiết kế từ 1980s không có xác thực. Phân tích kỹ thuật từ SIP header đến PSTN Gateway, tại sao Việt Nam đặc biệt dễ bị tấn công.

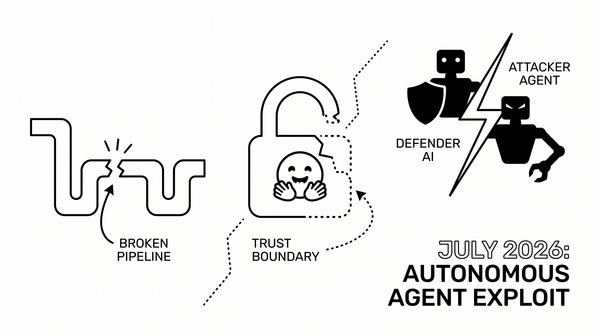
Mổ xẻ từng byte con RAT trong vụ axios npm supply chain attack: 5 bugs trong malware của hacker Bắc Triều Tiên nhưng vẫn compromise hàng nghìn máy trong 3 tiếng.

Lỗ hổng ẩn giấu gây thiệt hại hàng triệu đô chỉ trong tích tắc

XSS là lỗ hổng web phổ biến và cũng là điểm khởi đầu lý tưởng để hiểu cơ chế bảo mật trình duyệt. Bài viết này không chỉ dừng lại ở việc bật `alert()` đâu.
Đo vận tốc ánh sáng là bài toán 300 năm, mà cốt lõi chỉ một mẹo: không bao giờ bấm giờ cho ánh sáng, chỉ đo hệ quả của nó lên thứ chậm hơn.

PgBouncer không phải feature bị thiếu. Nó là một process phải tồn tại, vì cái ranh giới nó đứng thì không Django lẫn Postgres nào sở hữu được.

Đấu tố cắt đứt mọi sợi dây ngang trong một đám người, chỉ chừa lại sợi dây dọc đi lên trên. Nó dùng được từ bàn ăn gia đình đến Bắc Triều Tiên, và chưa bao giờ hỏng ở đúng cái việc nó sinh ra để làm.
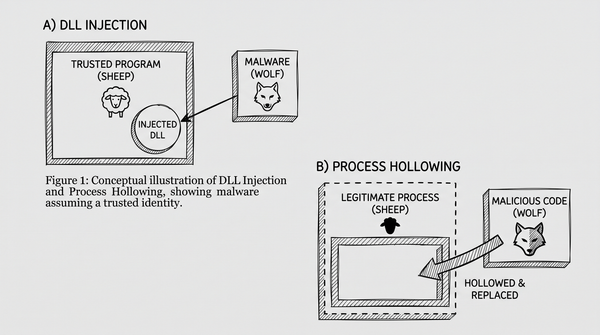
DLL injection và process hollowing là hai kỹ thuật malware giấu mình trong process hợp pháp, né antivirus. Giải thích dễ hiểu qua analogy, ví dụ Stuxnet 2010 và lý do Windows không thể cấm.

NHNN nới room bốn lần trong 60 ngày. Mình không tin cách đọc 'xã rộng lượng': dựng dự báo bằng số, từ nay đến 2028 các xưởng vay (ngân hàng) phải đi gom gạo (vốn) ầm ầm - bán suất hùn, vay bao đỗ, giành từng bồ tiền gửi. Cổ đông nhạt bữa, biên lời bị ép. Còn chợ nhà đất không sập, chỉ ngừng họp.
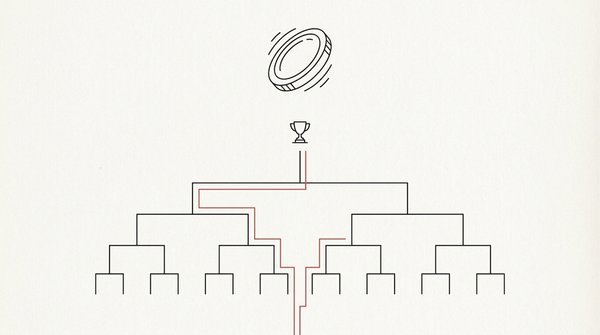
Công thức viral 'the team that beat the team that beat Japan' đúng 4/4 kỳ World Cup. Toán của cây knockout nói: chuyện đó bình thường đến mức đáng thất vọng.

Hướng dẫn Yocto Project cho người mới: hiểu Poky, BitBake, layers, recipes, build image Linux chạy QEMU, tùy chỉnh image và tạo layer riêng.

Cảm giác thông minh hơn xung quanh, ghét sự cảm tính của người khác, làm đúng mà vẫn làm người ta tổn thương. Mình sống trong cảm giác đó khá lâu, rồi tính ra nó là nước đi phi lý trí nhất trên bàn cờ, theo đúng định nghĩa lý trí mà mình tôn thờ.
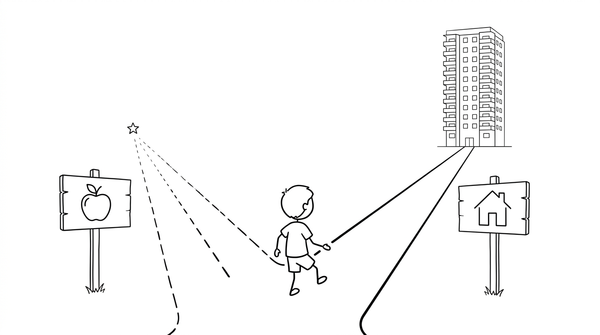
Trẻ con Việt Nam không sai khi muốn làm Phạm Nhật Vượng thay vì Steve Jobs. Chúng đang giải đúng bài toán tối ưu mà người lớn xây cho chúng.

Giải thích MTD subsystem trong Linux kernel: từ vật lý floating-gate transistor, NOR vs NAND, đến UBI/UBIFS và quy trình flash NAND thực tế.

Anh đồng nghiệp người Đức nói 'build quality in' ở mọi kickoff, chưa bao giờ ở lúc cuối. Mình gật gù nửa năm rồi mới hiểu, đúng lúc tự tay tắt CI để kịp hotfix.

Game Theory giả định bạn lý trí hoàn hảo. Quan Liêu Theory chỉ giả định bạn đang cố sống sót đến hết giờ làm. Một lý thuyết hoàn chỉnh, kèm định lý, công thức, và citation thật, về vì sao sếp bạn dở mà vẫn lên chức.